



I. Les bases de Mongo DB : présentation▲
MongoDB est la base de données NoSQL orientée documents de référence dont les données sont stockées sous forme de structures JSON.
Mongo DB propose un driver Java propriétaire, pour accéder aux données et accessible en ligne.
Cette API fournit un ensemble de classes minimales pour interagir avec Mongo.
I-A. Les classes minimales de Mongo ▲
MongoClient : représente un client de connexion à Mongo, avec un mécanisme interne de pool. Dans la plupart des applications une seule instance de cette classe sera définie. Cet objet va permettre d'interagir avec l'instance de Mongo.
MongoClient mongoClient = new MongoClient();
DB : est une représentation physique de la base de données. Son utilisation est la suivante (avec en paramètre le nom de la base de données) :
DB db = mongoClient.getDB("test");
DBCollection : est un squelette qui représente une collection de documents (qui sera récupérée lors d'une opération de recherche avec en paramètre le nom de la collection).
DBCollection dogs = db.getCollection("Dog");
DBObject : est une représentation d'un document de la base de données. Sa récupération se fait sur le résultat d'une recherche (qui a retourné une DBCollection).
DBObject dog = dogs.findOne();
DBCursor : est un itérateur sur une population de documents. Son utilisation se fait en lien avec une expression de recherche (qui représente une requête sur un ensemble de documents) :
2.
3.
BasicDBObject query = new BasicDBObject();
query.put("name", Pattern.compile(".*"));
DBCursor cursor = dogs.find(query);
Ce code n'est pas portable et est dépendant de la structure de stockage. Il est en outre vite verbeux. Nous allons maintenant voir les solutions apportées par Spring Data et Hibernate OGM.
II. Spring Data▲
Spring Data facilite l'accès aux bases de données NoSQL. C'est un projet chapeau qui définit un ensemble de sous-projets pour accéder à différentes technologies NoSQL : MongoDB, Neo4J, Cassandra, Hadoop…
Spring Data pour Mongo DB est une sous-partie de l'écosystème Spring Data. Il fournit un modèle de programmation pour accéder à cette base de données orientée document.
II-A. Configuration▲
Comme dans tous les projets Spring, la configuration passe par un fichier de configuration XML ou par une configuration complète en annotations. Spring Data pour Mongo DB fournit un namespace pour déclarer et configurer une connexion à la base de données Mongo.
2.
3.
xmlns:mongo="http://www.springframework.org/schema/data/mongo"
xsi:schemaLocation="http://www.springframework.org/schema/data/mongo
http://www.springframework.org/schema/data/mongo/spring-mongo-1.0.xsd
Les deux balises suivantes définissent les paramètres de connexion à la base (nom du serveur, port de connexion et nom de la base de données) :
2.
<mongo:mongo host="127.0.0.1" port="27017" />
<mongo:db-factory dbname="test" />
On peut aussi définir un template pour interagir avec Mongo.
2.
3.
4.
<bean id="mongoTemplate"
class="org.springframework.data.mongodb.core.MongoTemplate" >
<constructor-arg name="mongoDbFactory" ref="mongoDbFactory" />
</bean>
La configuration Maven d'un projet Spring Data Mongo est la suivante :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>3.2.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>3.2.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-mongodb</artifactId>
<version>1.2.0.RELEASE</version>
</dependency>
II-B. Les classes / annotations▲
L'annotation @Document (qui n'est pas obligatoire) permet de spécifier qu'une classe sera mappée sur un document JSON. Le paramètre précise le nom de la collection qui va recevoir l'objet.
2.
@Document(collection = "users")
public class User {…}
L'annotation @Id déclare un attribut comme identifiant de l'objet JSON (chaque document Mongo définit un identifiant unique id).
2.
@Id
private String id;
L'annotation @DBRef va lier un document JSON à un autre document JSON du modèle. La référence est faite par l'identifiant unique de l'objet référencé. Cette référence est ajoutée à la structure JSON de l'objet référençant, les insertions et récupérations peuvent ainsi se faire en cascade.
2.
3.
public class User {
@DBRef
private Address address;
II-C. Mongo Template▲
L'objet MongoTemplate facilite les opérations sur l'instance de Mongo. Il permet, par exemple, de faire des opérations de recherche sur une collection de documents :
List<User> savedUsers = mongoTemplate.findAll(User.class);
Il est aussi possible d'exécuter des requêtes avec des critères de recherche évolués :
Query searchUserQuery = new Query(Criteria.where("username").regex(Pattern.compile("user.*")));
Mongo ne propose pas de langage d'interrogation type SQL, la recherche se fait par exemple sur la valeur du champ username qui doit correspondre à une expression régulière (user.*).
Le template propose des méthodes pour la mise à jour et la suppression de données. Ces opérations passent également, au préalable, par une requête de recherche :
- mise à jour
mongoTemplate.updateFirst(searchUserQuery, Update.update("password", "new password"), User.class);
- suppression
mongoTemplate.remove(searchUserQuery, User.class);
Ce code reste encore fortement lié à la structure de stockage sous-jacente. Pour s'en affranchir, Spring Data propose les mécanismes de Repository, qui implémentent une logique d'interactions spécifiques à la couche de données sous-jacente.
II-D. Les repository▲
La finalité des Repository est de réduire considérablement le couplage à une couche de données définie et ainsi de fournir un code interopérable. L'effort d'adaptation du code est grandement réduit. Spring Data fournit une hiérarchie d'interfaces Repository qui adresse un ensemble de problématiques classiques.
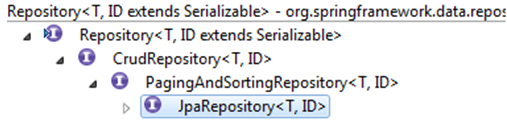
L'interface CrudRepository implémente les opérations de sauvegarde, de mise à jour et de suppression sur la couche de données cible.
II-E. Configuration Spring▲
Un projet utilisant l'écosystème Spring Data fournit une configuration qui lui est spécifique par l'intermédiaire d'un template particulier. Les interactions avec la couche de données s'appuient alors sur ce template spécifique. La configuration pour Mongo est la suivante :
<mongo:repositories base-package= "tk.test.mongodb.repository"/>.
L'ensemble des Repository annotés avec @Repository seront scannés dans le package précisé.
II-F. Utilisation des Repository▲
On peut utiliser le Repository propre à chaque Mongo DB :
2.
@Repository
public interface UserMongoRepository extends MongoRepository<User, String> {}
On pourra préférer d'utiliser le Repository fourni par Spring Data pour plus de modularité.
2.
@Repository
public interface UserRepository extends CrudRepository<User, String> {}
II-G. Opérations personnalisées▲
Il est possible d'étendre les opérations d'un Repository, Spring Data fournit ainsi un langage d'expressions pour déclarer des opérations de recherches plus évoluées :
findByUserNomAndPrenom(String nom, String prenom).
La recherche s'effectuera alors sur un objet User dont les propriétés nom et prénom ont les valeurs passées en paramètre. Pour plus d'informations, consulter Spring Datastore Document.
Il est possible avec le mécanisme de Repository de Spring de s'affranchir en partie de la structure de stockage sous-jacente, toutefois il reste quelques spécificités, notamment concernant la déclaration des entités (Cassandra et MongoDB notamment).
III. Hibernate OGM / JPA▲
Hibernate OGM est une extension de Hibernate qui propose un support des bases de données NoSQL. Sa mise en place est aussi simple que la mise en place d'un projet Hibernate classique. La configuration se fait par la définition d'un fichier persistence.xml.
2.
3.
4.
5.
6.
7.
8.
9.
<persistence-unit name="test-pu">
<provider>org.hibernate.ogm.jpa.HibernateOgmPersistence</provider>
<properties>
<property name="hibernate.ogm.datastore.provider" value="org.hibernate.ogm.datastore.mongodb.impl.MongoDBDatastoreProvider"/>
<property name= "hibernate.ogm.mongodb.database" value= "test"/>
<property name= "hibernate.ogm.mongodb.host" value= "localhost"/>
<property name= "hibernate.ogm.mongodb.port" value= "27017" />
</properties>
</persistence-unit>
hibernate.ogm.datastore.provider spécifie le fournisseur de connexions, il prend la valeur d'une classe spécifique pour Mongo.MongoDBDatastoreProvider).
Ensuite viennent les paramètres qui matérialisent le serveur Mongo : le port et le nom de l'instance. Il faut également configurer Maven pour que celui-ci importe les dépendances nécessaires à Hibernate OGM.
2.
3.
4.
5.
6.
7.
8.
9.
10.
<dependency>
<groupId>org.hibernate.ogm</groupId>
<artifactId>hibernate-ogm-core</artifactId>
<version>4.0.0.Beta4</version>
</dependency>
<dependency>
<groupId>org.hibernate.ogm</groupId>
<artifactId>hibernate-ogm-mongodb</artifactId>
<version>4.0.0.Beta4</version>
</dependency>
III-A. Les annotations▲
@Entity
Cette annotation va indiquer à Hibernate OGM que notre classe est une entité Hibernate et donc qu'elle sera sauvegardée dans Mongo sous la forme d'un document JSON.
@Entity public class Etudiant {…}
@Id, @GeneratedValue, @GenericGenerator
Ces annotations précisent la stratégie de génération des propriétés id du document JSON.
@Column
Précise que l'attribut de l'instance est une propriété du document JSON (par défaut tous les attributs d'instance accessibles sont enregistrés).
@OneToOne, @OneToMany, @ManyToOne, @ManyToMany
Hibernate OGM peut définir des liaisons entre documents.
Dans le cas des liaisons unitaires, les documents seront enregistrés en base avec une propriété spécifique de l'objet JSON qui représentera l'id du document lié.
Dans le cas des liaisons multiples (@ManyToMany), Hibernate OGM créera une table de jointure avec les id des documents impliqués dans cette liaison.
2.
3.
4.
5.
public class Etudiant {
@OneToOne
public Personne user;
@ManyToMany
public List<Cours> cours;
Les liens entre documents sont donc gérés par Hibernate OGM, le développeur se contentant de les déclarer.
IV. Le mot de la fin▲
Les technologies NoSQL sont matures et robustes, mais bien qu'elles proposent des API pour les exploiter, ces dernières sont hétérogènes, car propres à chaque fournisseur.
La mise en place des solutions Hibernate OGM et Spring Data sont simples. Le premier, par sa simplicité et sa robustesse, est une technologie puissante qui repose sur des standards éprouvés. Cette solution pourrait facilement répondre à la problématique de mise en place d'un ORM sur une base de données Mongo.
Quant à Spring Data, il semble largement tirer son épingle du jeu. Même si sa mise en œuvre est un peu moins efficace que Hibernate OGM et son utilisation plus verbeuse, il propose une grande modularité et une grande souplesse de par une API intuitive, ainsi qu'un panel de connecteurs plus variés que ceux de Hibernate OGM (Cassandra, Neo4j, Couch DB, Mongo DB, Hadoop). Il persiste néanmoins une certaine hétérogénéité dans son utilisation sur les différentes solutions NoSQL, ainsi même avec les Repository, il est difficile de s'affranchir totalement de la structure de stockage.
Il existe également d'autres solutions, telles que DataNucleus, Morphia ou Kundera. Mais, après première analyse, il semble que ces solutions soient moins répandues et moins souples que peuvent l'être Hibernate OGM ou Spring Data.
Par exemple, dans le cas de DataNucleus, l'outil est moins facile à prendre en main et à mettre en place : il faut prétraiter les entités pour les instrumenter et leur ajouter du code spécifique à l'API (pour que DataNucleus puisse les manipuler).
Nous proposerons une étude de cet ensemble de solutions alternatives dans un prochain article.
V. Remerciements▲
Cet article a été publié avec l'aimable autorisation de la société SQLISoat qui est le partenaire de référence des entreprises dans la définition, la mise en œuvre et le pilotage de leur transformation digitale.
Nous tenons à remercier Jacques Jean pour sa relecture attentive de cet article et milkoseck pour la mise au gabarit.