



I. Découverte de JEE 7 batch processing▲
I-A. Problématique▲
Les jobs ou batches sont une problématique récurrente dans les applications. Classiquement, on a besoin de traitement batch pour injecter/extraire des données depuis un SGBDR, certains réseaux sociaux par exemple ont un gros besoin de batch. On peut imaginer qu'ils utilisent deux types de SGBD : un relationnel pour l'enregistrement et un no-sql pour l'affichage. Il est alors vital d'avoir une solution éprouvée pour copier les données saisies vers la base no-sql.
La problématique de traitement batch est très répandue et assez mal adressée dans le monde Java. Il existe quelques solutions assez répandues, parmi lesquelles on peut citer :
- quartz qui est framework pour planifier des tâches/batches. Néanmoins cet outil ne propose rien concernant la constitution du traitement. Finalement, tout le développement du batch (reprise sur erreur, checkpoints, partitionnement, traitement parallèle, enchaînement des étapes, workflow) reste à la charge du développeur ;
- les scripts Shell : cette solution est éprouvée, mais ne s'intègre pas au contexte d'un serveur d'application. Elle n'est pas liée à un serveur d'application lorsque la tâche est planifiée avec une crontab. De plus dans cette solution le développeur doit gérer la création complète du batch : l'enchaînement des étapes, des checkpoints ou les traitements parallèles. On peut également s'aider d'un ordonnanceur tel AutoSys, qui reste à mon sens une solution plutôt orientée administrateur UNIX et non plus « javaiste » ;
- spring batch est un framework très proche de JEE batch. Cette solution antérieure est efficace et mature, mais ne s'intègre pas totalement au contexte d'un serveur d'application (quid de la gestion des threads dans les traitements parallèles). De plus il peut être gênant de devoir gérer un framework additionnel à JEE : compatibilité avec la version de JEE, montée de version, interaction lors de l'utilisation d'un socle de développement, intégration et utilisation sous WAS et ses différents classloaders.
C'est pour cela que l'API JEE batch se doit de répondre et de résoudre les diverses problématiques illustrées par les quelques exemples ci-dessus. De plus JEE doit suivre les changements et notamment pouvoir s'adapter à ce que propose le monde Spring pour ainsi rester un substitut fiable à Spring.
C'est pourquoi ce framework propose une API (dans le package javax.batch) qui s'intègre totalement à l'univers JEE 7. Elle propose une solution fiable et robuste pour la mise en place de traitements batch et pour la définition du comportement et du workflow de ces batches au sein d'un serveur d'application.
I-B. Présentation▲
La JSR 352 a pour vocation de permettre l'exécution de jobs (ou traitements batch) dans le contexte d'une application JEE et donc d'un serveur d'application (Glassfish dans le cas présent).
Elle permet entre autres de définir des checkpoints, de supporter les transactions, elle permet aussi de morceler et paralléliser les traitements. Elle s'intègre à JEE et peut profiter, par exemple, des fonctionnalités des serveurs d'application : injection de dépendances (CDI), injection de contexte JNDI, gestion des transactions (JTA), etc.
I-C. Architecture générale▲
I-C-1. Architecture générale d'un batch▲
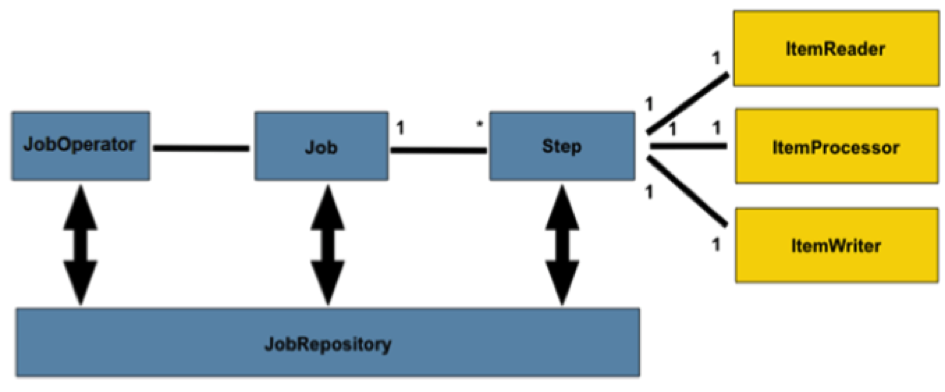
Ci-dessus sont représentés les concepts clés de l'architecture. Un job définit des étapes (step), qui peuvent se suivre le modèle ItemReader/ItemProcessor/ItemWriter. L'instance de JobOperator propose une manière d'interagir avec un batch (il peut l'arrêter, le démarrer, le redémarrer, etc.) Chacun des éléments JobOperator, Job et Step sont associés à un unique JobRepository qui contient les métadonnées associées à l'exécution courante.
I-C-2. Éléments constitutifs d'un job▲

Le Job est l'élément qui encapsule l'ensemble des traitements d'un batch. Un Step est la définition d'une étape atomique. L'objet StepExecution correspond à une exécution particulière d'un Step. L'objet StepExecution pourra par exemple contenir des métadonnées décrivant l'exécution en cours. Un Job peut compter plusieurs Step enchaînés.
L'objet JobInstance correspond à l'exécution logique d'un Job. Un Job peut contenir plusieurs JobInstance, car le Job peut être lancé par exemple une fois par jour. L'objet JobExecution pourra contenir les métadonnées décrivant l'exécution en cours.
L'objet JobExecution correspond à une exécution particulière d'un Job. À chaque fois qu'un Job est lancé, une instance de JobExecution existe. Une instance de job peut être exécutée plusieurs fois : par exemple dans le cas d'un échec si l'on procède à un nouveau lancement.
Par ailleurs comme un Job correspond à plusieurs Step, une instance de JobExecution correspond également à plusieurs instances de StepExecution.
La configuration se fait de façon déclarative dans un fichier XML (couramment appelés « Job XML »).
I-C-3. Exécution d'un job▲
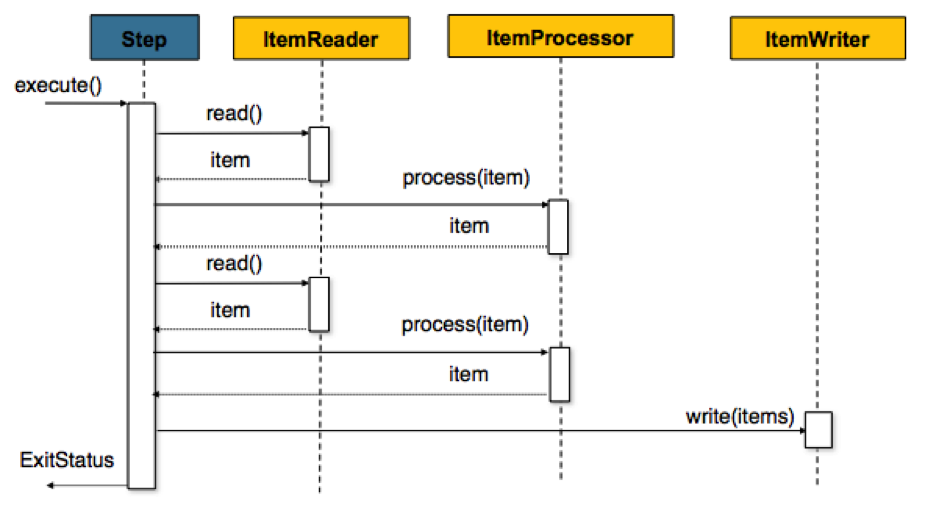
Dans le diagramme ci-dessus, pour chaque élément (item) de l'étape (des lignes d'un fichier par exemple), le Step invoque n fois le couple read()/process(). Une fois la liste d'éléments constituée, l'opération Write est appelée sur ces éléments pour, par exemple, les stocker en base, les enregistrer dans un fichier, les envoyer vers un flux de sortie, etc.
Nous verrons dans la partie suivante quels sont les éléments principaux constituant un job et comment les définir à l'aide de l'API de batch de jee7. Nous présenterons ainsi les éléments step (batchlet et chunck), nous présenterons également les points de sauvegarde (checkpoints), nous préciserons finalement comment l'API gère les erreurs lors de l'exécution des traitements.
II. Définir un job avec l'API de batch JEE 7▲
Nous avons vu précédemmentDécouverte de JEE 7 batch processing de façon théorique, comment une API de batch est structurée et quels doivent être les éléments constitutifs d'un step (partie de traitement unitaire d'un batch). Nous avons également vu en détail comment cette API doit se conformer au flot d'exécution d'un batch.
Nous allons présenter ci-dessous comment JEE 7 implémente les concepts vus précédemment et comment définir les éléments du batch, ce qui nous permettra de présenter les différences entre batchlet et step. Nous traiterons ensuite des checkpoints qui présentent un mécanisme point de sauvegarde. Finalement nous discuterons de la gestion des erreurs par cette API.
II-A. Les étapes d'un batch, l'élément <Step>▲
- L'API du batch propose deux versions de la notion de Step : les batchlet et les chunk.
II-A-1. L'élément <batchlet>▲
Un élément batchlet est une étape qui peut être utilisée pour un traitement en tâche de fond qui ne nécessite pas de suivre le pattern Read/Process/Write. L'interface Batchlet possède deux méthodes :
2.
public String process() throws Exception;
public void stop() throws Exception;
La définition XML se fait alors de la façon suivante :
2.
<step id="batchlet-0">
<batchlet ref="MonBatchlet" />
Avec l'attribut ref qui qualifie un nom complet ou un alias (exposé par CDI) pointant vers une implémentation de l'interface Batchlet.
II-A-2. L'élément <chunck>▲
Un chunk est une étape unitaire qui suit le modèle Reader/Processor/Writer. La définition se fait de la façon suivante :
2.
3.
4.
5.
6.
7.
<step id="id">
<chunk checkpoint-policy="custom" item-count="1">
<reader>reader</reader>
<writer>writer</writer>
<processor>processor</processor>
</chunk>
</step>
Avec les valeurs des tags (reader, writer et processor) qui qualifient un nom complet ou un alias (exposé par CDI) pointant respectivement vers une implémentation de ItemReader, ItemWriter et ItemProcessor.
Le paramètre check-point-policy précise quelle stratégie de checkpoints est mise en place. La valeur item définit un checkpoint qui interviendra à l'issue d'un nombre d'éléments, cet intervalle étant défini par la valeur de item-count (la valeur de item-count n'est pas prise en compte dans le cas de ckeck-point-policy à custom).
II-B. L'élément <reader>▲
C'est la classe qui va lire les éléments disponibles sur le flux d'entrée, elle doit implémenter les méthodes suivantes :
2.
3.
4.
void open(Serializable checkpoint) throws Exception;
void close() throws Exception;
T readItem() throws Exception;
Serializable checkpointInfo() throws Exception;
- readItem va lire l'élément suivant disponible dans le flux et construire un objet résultat ou renvoyer null si plus aucun élément n'est disponible,
- open permet d'exécuter des traitements avant la lecture, elle reçoit en entrée le dernier checkpoint généré pour ce reader,
- close est exécutée en fin de lecture des items du flux,
- checkPointInfo récupère les dernières informations correspondant au checkpoint enregistré.
II-C. L'élément <processor>▲
Une fois un item lu par le reader, la méthode processItem du processor prend le relais. La classe processor doit implémenter la méthode suivante :
R processItem(T item) throws Exception;
Un élément est traité par cette méthode et transformé. L'ensemble des éléments traités est alors passé au writer.
II-D. L'élément <writer>▲
L'ItemWriter va se charger d'envoyer la liste de résultats sur un flux de sortie par exemple. Le writer doit implémenter les méthodes suivantes :
2.
3.
4.
void open(Serializable checkpoint) throws Exception
void close() throws Exception
void writeItems(List<T> items) throws Exception
Serializable checkpointInfo() throws Exception
Les méthodes close, open et checkpointInfo sont similaires à celles de l'ItemWriter.
La méthode writeItems va recevoir les éléments traités par le couple Reader/Processor et les envoyer par exemple vers le flux de sortie, les stocker en base, les enregistrer dans un fichier, etc.
II-D-1. Les checkpoints▲
Dans un cadre transactionnel, un checkpoint va définir une marque utilisable par le processus batch, celle-ci renseignant le batch sur l'étape où il se trouve dans le traitement (par exemple dans le cas d'une reprise ou d'un rollback). Ce checkpoint est transmis au Reader, il peut être créé en début de traitement lors de l'appel à la méthode open.
Le checkpoint peut contenir toute information relative à l'exécution en cours (il doit toutefois implémenter l'interface Serializable). Il peut par exemple contenir le numéro de l'élément lu, le numéro de ligne dans un fichier en entrée, etc. L'objet checkpoint renvoyé par la méthode checkpointInfo.
II-D-1-a. Personnalisation des checkpoints : l'élément <checkpoint-algorithm>▲
Par défaut, l'enregistrement du checkpoint se déclenche suite à un certain nombre d'éléments (Item). Il est possible de personnaliser ce comportement en définissant un algorithme.
Pour cela la balise checkpoint-algorithm fait le lien avec une classe implémentant l'interface CheckpointAlgorithm et qui définit les méthodes :
2.
3.
4.
public int checkpointTimeout() throws Exception;
public void beginCheckpoint() throws Exception;
public boolean isReadyToCheckpoint() throws Exception;
public void endCheckpoint() throws Exception;
La méthode la plus importante est isReadyToCheckpoint, elle va indiquer au batch s'il doit démarrer un nouveau checkpoint.
Exemple : effectuer un checkpoint toutes les cinq secondes.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
public class TestCheckPointAlgorithm extends AbstractCheckpointAlgorithm {
[…]
private long time;
public TestCheckPointAlgorithm() {
time = System.currentTimeMillis();
}
public boolean isReadyToCheckpoint() throws Exception {
boolean result = System.currentTimeMillis() - time >= 5000l && time != 0l;
[…]
return result;
}
[…]
beginCheckpoint et endCheckpoint sont appelées respectivement en début et fin de checkpoint.
II-D-2. Note sur les transactions▲
Chaque étape de type chunk peut être exécutée dans une transaction qui lui est propre. Lorsque le nombre d'éléments traités correspond à la valeur de la configuration et que la transaction est globale au Step, les données sont commitées. Pour un checkpoint custom, la transaction est validée si l'algorithme de checkpoint renvoie true pour l'appel à isReadyToCheckpoint.
La durée de la transaction globale est définie par la propriété suivante : javax.transaction.global.timeout={durée en secondes} - la valeur par défaut est de 180 secondes.
Cette valeur peut être passée en paramètre au niveau de la définition du Step.
2.
3.
4.
5.
<step id="…">
<properties>
<property name="javax.transaction.global.timeout" value="600"/>
</properties>
</step>
II-D-3. Gestion des erreurs▲
Toute exception renvoyée par un listener qui est défini au niveau racine provoque l'arrêt du Job avec un statut FAILED.
Toute exception envoyée par un Job ou par un élément de niveau Step pendant le traitement des étapes provoque l'arrêt de l'étape et du Job associé avec un statut FAILED.
Par défaut, quand une exception est remontée depuis un traitement de type chunk, le Job se termine avec un statut FAILED. Il est toutefois possible d'outrepasser ce comportement avec un certain nombre de balises.
- skippable-exception-classes permet d'ignorer des exceptions ou de poursuivre si une exception survient. Une liste d'exceptions peut-être précisée avec les sous-balises include et exclude (la valeur étant le nom complet des classes d'exceptions). Il peut y avoir plusieurs occurrences de ces sous-balises.
Par exemple :
2.
3.
4.
<skippable-exception-classes>
<include class="java.lang.RuntimeException"/>
<exclude class="java.io.IOException"/>
</skippable-exception-classes>
- retryable-exception-classes permet de préciser les exceptions pour lesquelles l'élément chunk va essayer à nouveau de s'exécuter. Comme ci-dessus, il est possible de préciser des listes d'exclusion et d'inclusion des exceptions.
Exemple :
2.
3.
<retryable-exception-classes>
<include class="java.lang.IllegalArgumentException"/>
</retryable-exception-classes>
On peut préciser que le batch n'effectue pas de rollback lorsque des exceptions surviennent avec la balise no-rollback-exception-classes :
2.
3.
<no-rollback-exception-classes >
<include class="java.lang.IllegalArgumentException"/>
</no-rollback-exception-classes>
Toute tâche de type batchlet qui lève une exception interrompt le traitement du Job avec un statut FAILED.
Nous avons vu dans cette partie les éléments principaux permettant la mise en œuvre d'un bacth (step, transaction, gestions des erreurs et points de sauvegarde).
Nous verrons dans la partie suivante comment s'opère la programmation avancée des batches. Pour cela nous présenterons l'utilisation des listeners sur les différents éléments du batch ; nous discuterons des outils permettant la création d'un flot d'exécution, des outils pour le morcellement des étapes ; finalement nous ferons le point sur le paramétrage des éléments du batch.
III. Programmation avancée des batches▲
Nous avons vu dans la partie précédente les éléments principaux permettant la mise en œuvre d'un batchDéfinir un job avec l'API de batch JEE 7 (step, transaction, gestions des erreurs et checkpoints).
Nous allons présenter ci-dessous la programmation avancée des batches avec l'API de batch de JEE7, ceci passant par la définition de listeners, par la mise en place de flots d'exécutions qui permettent notamment des branchements conditionnels, des redirections, etc. Finalement nous aborderons le paramétrage avancé des étapes du batch pour fournir les paramètres nécessaires à nos différents éléments.
III-A. Les listeners▲
Il est possible d'attacher des listeners à peu près pour chacun des éléments du batch parmi lesquels SepListener et ItemProcessListener.
III-A-1. Steplistener▲
L'implémentation définit deux méthodes beforeStep et afterStep. Sa déclaration se fait au niveau de l'élément Step du fichier de configuration XML. Il peut être utilisé par exemple pour faire une action spécifique avant une étape et libérer des ressources en fin d'étape.
Exemple : affichage des informations sur l'exécution du Job.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
public class InfoJobListener implements StepListener {
@Inject
StepContext<?, ?> stepCtx;
@Override
public void beforeStep() throws Exception {
System.out.println("Start Step " + stepCtx.getStepName());
}
@Override
public void afterStep() throws Exception {
System.out.println("End step");
}
}
2.
3.
4.
5.
6.
7.
<step id="chunck-step">
[…]
<listeners>
<listener ref="InfoJobListener"></listener>
</listeners>
[…]
</step>
III-A-2. Itemprocesslistener▲
Il définit trois méthodes beforeProcess, afterProcess et onProcessError.
Les méthodes beforeProcess et afterProcess sont déclenchées avant et après le traitement d'un l'élément par le processor, la méthode onProcessError est appelée si le traitement de l'élément par le processor lève une exception.
Exemple :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
public class FileItemProcessListener implements ItemProcessListener<String, LineItem> {
@Inject
StepContext<?, Serializable> stepContext;
@Override
public void beforeProcess(String item) throws Exception {
System.out.println("before processing step " + stepContext.getStepName());
}
@Override
public void afterProcess(String item, LineItem line) throws Exception {
System.out.println("after processing step " + stepContext.getStepName());
}
@Override
public void onProcessError(String item, Exception exception) throws Exception {
System.out.println("error processing item " + item + " in step " + stepContext.getStepName());
System.out.println(exception);
}
}
2.
3.
4.
5.
6.
7.
<step id="chunck-step">
[…]
<listeners>
<listener ref="FileItemProcessListener"></listener>
</listeners>
[…]
</step>
III-B. Flot d'exécution▲
III-B-1. L'élément suivant▲
Il est possible de chaîner des étapes en précisant l'étape suivante dans le fichier XML :
- en définissant l'attribut next qui a pour valeur l'id de l'étape que l'on veut chaîner.
<step id="chunck-step-1" next="chunck-step-2">
- en utilisant l'élément next, sous-élément de step. Cet élément propose plusieurs attributs : on et to. L'attribut on définit pour quelle valeur de statut (positionné lors de la terminaison de l'étape), ou pour quelle valeur renvoyée par le decider, la transition aura lieu. L'attribut to précise l'identifiant de la prochaine étape (qui peut être de type step, flow ou split).
<next on="FAILED" next="step-job-FAILED">
III-B-2. Les éléments <flow>, <split> et <decision>▲
L'attribut flow permet de définir un ensemble d'étapes qui s'exécutent de façon unitaire et séquentielle. Il peut contenir des sous-éléments de type step, flow ou decision.
L'élément decision référence une implémentation de Decider, elle expose une méthode :
public String decide(StepExecution[] executions) throws Exception
Selon la valeur retournée, il est possible de brancher la suite du traitement vers un Step ou un autre.
Exemple :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
<flow>
<step id="step1">
[…]
</step>
<decision id="decision">
[…]
<next on="value1" to="step2"/>
<next on="value2" to="step3"/>
<stop on="value3" exit-status="status" />
</decision>
<step id="step2">
[…]
</step>
<step id="step3">
[…]
</step>
</flow>
L'élément split permet d'exécuter des séquences d'étapes (balise flow) de façon concurrente.
Exemple :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
<split id="split1">
<flow id="flow1">
<step id="step1">
[…]
</step>
</flow>
<flow id="flow2">
<step id="step2">
[…]
</step>
</flow>
</split>
III-C. Partition des étapes▲
La balise partition permet de partitionner un Step. Cet élément est composé des sous-balises mapper ou plan et optionnellement des sous-balises collector, analyzer et reducer.
Le plan et le mapper permettent de définir des propriétés d'exécution. L'élément plan permet de configurer le nombre de threads, le nombre de partitions ainsi que des paramètres via le fichier XML.
2.
3.
4.
5.
6.
7.
8.
9.
<plan partitions="2" threads="2">
<properties partition="0">
<property name="name0" value="value0"/>
</properties>
[…]
<properties partition="2">
<property name="name2" value="value2"/>
</properties>
</plan>
L'élément mapper définit une référence vers un objet de type PartitionMapper qui expose une méthode pour construire un PartitionPlan. Cet objet va contenir les propriétés relatives à chacune des partitions.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
public class FileItemMapper implements PartitionMapper {
public PartitionPlan mapPartitions() throws Exception {
PartitionPlanImpl plan = new PartitionPlanImpl();
plan.setPartitions(2);
plan.setThreads(2);
Properties properties = new Properties();
properties.setProperty("fineName", "test.csv");
Properties[] partitionProperties = new Properties[2];
partitionProperties[0] = properties;
plan.setPartitionProperties(partitionProperties);
return plan;
}
}
L'élément collector récupère les données intermédiaires depuis une ou plusieurs partition(s), il les soumet à une instance de PartitionAnalyzer pour les traiter.
Une instance de PartitionReducer récupère les données intermédiaires qui seront ensuite agrégées.
Exemple :
2.
3.
4.
5.
<partition>
<collector ref="FileItemCollector"></collector>
<analyzer ref="FileItemAnalyzer"></analyzer>
<reducer ref="FileItemReducer"></reducer>
</partition>
III-D. Paramétrage▲
III-D-1. Récupération des propriétés▲
Les propriétés peuvent être récupérées au niveau du JobContext ou du StepContext, tout dépend à quel niveau sont définies les balises properties. Si elles sont définies directement en dessous de l'élément Job, elles sont globales à tous les Step, c'est alors le JobContext qui les contient. Sinon, elles sont locales au Step et sont dans l'objet StepContext courant.
III-E. Injection des contextes d'exécution▲
Il est possible d'utiliser CDI pour récupérer ces contextes en utilisant l'annotation @Inject :
2.
3.
4.
5.
@Inject
StepContext<?, ?> context;
@Inject
JobContext<?> jobContext;
L'accès aux propriétés se fait alors simplement par context.getProperties().
III-F. Passage de valeurs dans le contexte d'exécution▲
Les contextes exposent deux jeux de méthodes pour conserver des objets durant un Step (StepContext) ou un Job (JobContext).
Ces contextes proposent deux types de valeurs utilisateur : une qui ne sera pas sauvegardée (transient) et une qui sera enregistrée dans le checkpoint de l'étape (persistante). Il est alors possible de conserver des valeurs pendant un job, pendant un step ou même de récupérer les valeurs transient lors d'un nouveau lancement depuis un checkpoint donné.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
public class StepListenerWithData implements StepListener {
private static final String FILE_NAME = "fileName";
@Inject
StepContext<Object, Serializable> context;
@Override
public void beforeStep() throws Exception {
Serializable nonTransientData = …;
Object transientData = …;
context.setPersistentUserData(nonTransientData);
context.setTransientUserData(transientData);
}
}
Les données du contexte seront disponibles durant l'exécution de cette étape via :
context.getTransientUserData(); et context.gePersistentUserData();.
Nous avons vu précédemment la structure complète d'un traitement batch, ainsi que l'importante palette d'outils qu'offre l'API JEE 7 pour la définition complète de ces traitements (step, listeners, point de sauvegarde, paramétrage, flots d'exécution…).
Nous allons voir dans la dernière partie à l'aide d'un exemple, comment mettre en œuvre notre traitement batch sur le serveur d'application GlasshFishDéploiement du batch sur le serveur d'application Glassfish : démarrage de notre batch, suivi de son exécution au cours du temps. Nous verrons ainsi en situation réelle comment notre batch s'intègre totalement à cette version de Glassfish et comment il est possible d'examiner les détails de son exécution en temps réel.
IV. Déploiement du batch sur le serveur d'application Glassfish▲
Nous allons voir dans cette partie comment exécuter notre traitement batch sur le serveur d'application GlasshFish. Nous pourrons ainsi découvrir que le déploiement du traitement se fait facilement sur les serveurs d'application se conformant à la spécification JEE 7, nous noterons aussi que l'on peut ainsi suivre facilement l'exécution du batch : son étape, son état, les paramètres qui lui sont passés…
IV-A. Configuration du batch▲
Le fichier de configuration XML du batch doit se trouver dans :
- META-INF/batch-jobs/ pour les packagings jar ;
- WEB-INF/classes/META-INF/batch-jobs/ pour les packagings war.
Par exemple :
Si on définit un Job de la façon suivante :
2.
3.
<job id="myJob">
[…]
</job>
Le nom du fichier XML sera : WEB-INF/classes/META-INF/batch-jobs/myJob.xml.
IV-B. Lancement et suivi du batch avec glassfish▲
Le lancement du batch peut se faire dans le contexte d'un serveur d'application, par exemple à l'aide d'un servlet, d'un EJB ou tout autre composant JEE.
Il peut se lancer de la façon suivante :
2.
3.
4.
5.
6.
JobOperator jobOperator = BatchRuntime.getJobOperator();
Properties props = new Properties();
// ajouter les propriétés nécessaires au batch…
jobOperator.start("myJob", props);
Ensuite on peut suivre le déroulement du batch avec la console d'administration de GlassFish.
Pour notre instance de serveur, il est possible de voir le(s) batch(es) exécuté(s) ou en cours d'exécution.
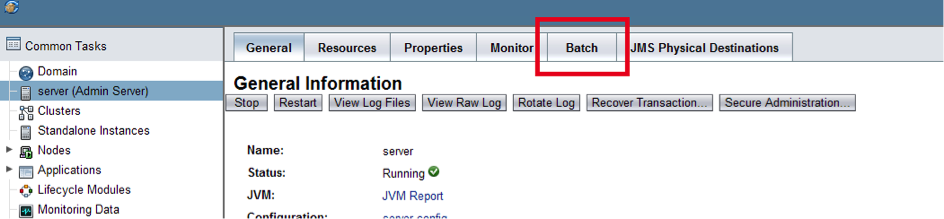
À chaque exécution d'un batch est associée un id unique. La console GlassFish va nous fournir des informations sur cette exécution particulière.
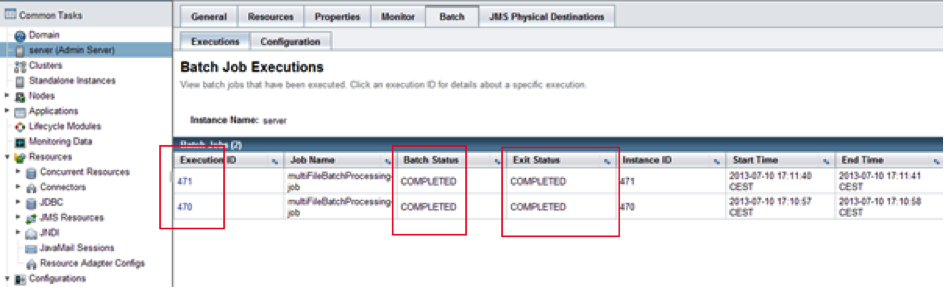
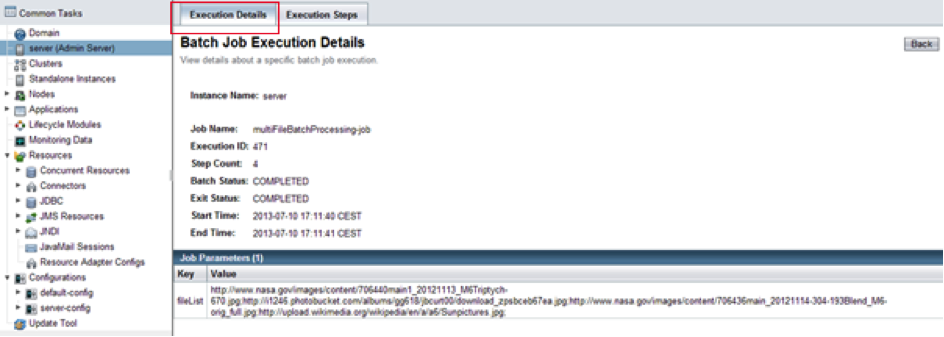
Nous pouvons ensuite voir l'ensemble des paramètres passés au batch lors de son exécution.
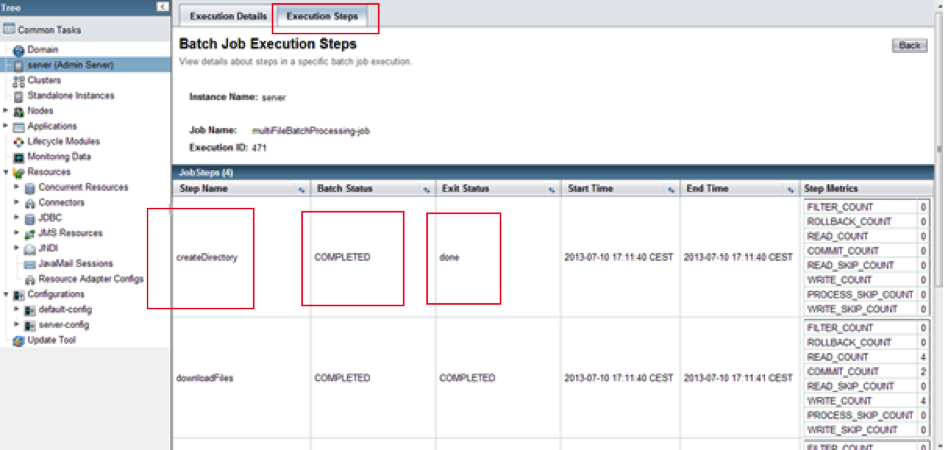
Ainsi que les informations détaillées sur le déroulement de chaque étape du batch : les noms du Step, l'état de terminaison du Step, des métriques pour chaque Step (nombre de lectures, rollback, écritures…), etc.
Exemples d'utilisation de l'API batch :
- un exemple complet d'utilisation de l'API batch pour télécharger des images : http://technology.amis.nl/2013/06/25/java-ee-7-creating-a-background-download-manager-using-java-batch-in-glassfish-4-0/
- un exemple complet pour l'analyse de fichiers de logs : https://docs.oracle.com/javaee/7/tutorial/batch-processing008.htm
- un ensemble d'exemples :
https://svn.java.net/svn/glassfish~svn/branches/arun/javaee7-samples/samples/batch/
V. Conclusion▲
L'API de batch que propose JEE 7 offre une grande palette de fonctionnalités à la fois simples et avancées pour la définition de traitements batch. Ces outils sont faciles à utiliser, souples et intuitifs pour permettre une mise en place de traitements complexes.
Cette brique de JEE se positionne donc clairement sur le même terrain que spring batch, mais bien que plus récente, elle bénéficie de en quelque sorte de l'expérience de son aînée et apparaît plus avancée à mon sens, car elle s'intègre complètement aux serveurs d'application récents (accès au contexte serveur, aux transactions, à CDI…).
Espérons vivement que cette API arrivera à se positionner comme un standard sur les différentes plateformes JEE, car elle réserve plein de promesses.
VI. Remerciements▲
Nous tenons à remercier Claude Leloup pour la relecture de cet article et ![]() milkoseck pour la mise au gabarit.
milkoseck pour la mise au gabarit.