



I. Comment gagner en rapidité en optimisant la JVM▲
L'optimisation dynamique concerne tous les langages s'exécutant dans la JVM : Java, Scala, Groovy, Jruby, Closure, JavaScript, mais aussi tout ce qui passe par une création de classe java intermédiaire : JSP, XSD (via xjc), WDSL (via wsimport).
Pour que les méthodes de la JVM soient transformées en code assembleur machine par la JVM, il faut deux conditions essentielles :
- Un nombre d'exécutions de cette méthode qui doit être au moins de 1500 fois pour le mode -client ou de 10 000 fois pour le mode -server ;
- Une taille de méthode inférieure à 8 ko de bytecode (difficile de donner un équivalent en nombre de ligne de code). Une taille supérieure à 8 ko empêche toute compilation en assembleur de cette méthode.
À noter que l'optimisation du code par le compilateur JIT (Just In Time) et la traduction du bytecode en assembleur est d'autant plus grande si l'inlining est activé. L'inlining est la fusion d'une méthode appelante et appelée afin d'avoir une vision globale du traitement et d'en faciliter l'optimisation. Une méthode dépassant les 1000 octets de bytecode ne pourra pas profiter d'inlining d'inclusion. Elle sera donc moins rapide, même si une partie de son code sera transformée en assembleur. La JVM utilise différents types d'inlining, nous y reviendrons plus tard.
Par défaut, les JVM 32 bits activent le mode -client alors que les JVM 64 bits ne proposent que le mode -server. Selon les traitements, il y a un rapport de 1 à quasiment 800 entre le mode -client et -server pour la même JVM.
À noter que dans des calculs intensifs, un rapport de 1 à 4 peut aussi exister entre un JDK 32 bits et 64 bits.
II. Jusqu'à quel point le code assembleur généré est optimisé par rapport à un compilateur C▲
La transformation du bytecode en code assembleur machine apporte un réel gain de vitesse. Pour s'en convaincre, et pour l'exemple, le calcul d'une valeur de la suite de Fibonacci compilée en C avec l'optimisation agressive -O3 a un même temps de réponse moyen que la JVM 1.7 d'IBM utilisant un cache de méthodes déjà compilées (via -Xshareclasses). L'écart est seulement de 31 % avec le JDK 8 64 bits (sans option particulière au lancement de la JVM).
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
#include <stdio.h>
#include <time.h>
unsigned int fib(unsigned int n){
unsigned int fibminus2 = 0;
unsigned int fibminus1 = 1;
unsigned int fib = 0;
unsigned int i;
if (n==0 || n==1) return n;
for(i=2;i<=n;i++) {
fib=fibminus1+fibminus2;
fibminus2=fibminus1;
fibminus1=fib;
}
return fib;
}
int main(int argc, char **argv) {
unsigned int n;
if (argc < 2) {
printf(" usage: fib n\n"
"Compute nth Fibonacci number\n");
return 1;
}
clock_t t1, t2;
t1 = clock();
n = atoi(argv[1]);
printf(" fib(%d) = %d\n ", n, fib(n));
t2 = clock();
int diff = (((float)t2 - (float)t1));
printf(" time : %d ms ",diff);
return 0;
}
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
class fib_nc {
public static long fib(long n) {
long fibminus2 = 0;
long fibminus1 = 1;
long fib = 0;
long i;
if (n==0 || n==1) return n;
for(i=2;i<=n;i++){
fib=fibminus1+fibminus2;
fibminus2=fibminus1;
fibminus1=fib;
}
return fib;
}
public static void main(String[] args) {
long n;
if (args.length < 1) {
System.out.println(" usage: fib n\nCompute nth Fibonacci number\n ");
return;
}
long t1, t2;
t1 = System.currentTimeMillis();
n = Long.valueOf(args[0]);
System.out.printf(" fib(%d) iteratif = %d\n ", n, fib(n));
t2 = System.currentTimeMillis();
System.out.println(" time in ms : " + (t2-t1));
}
}
NB : la ligne de commande à exécuter pour compiler sous Mingw32 est la suivante sous Windows : gcc fib.c -o fib.exe -O3.
II-A. Du code source à l'optimisation dynamique▲
La JVM est une machine virtuelle multilangage et le nombre de langages supportés n'a pas cessé de grandir. Certains langages se limitent à de l'interprétation (même si elle est plus rapide sous Java 7 grâce au InvokeDynamic), mais les plus utilisés proposent également un compilateur pour passer du monde Scala, Groovy, Jruby, Jython, JavaScript à un fichier .class en bytecode.
De plus, d'autres outils proposent de générer des classes Java qui à leur tour s'exécuteront dans la JVM. Les JSP sont transformées en servlet .java via jspc (ou jasper sur tomcat) puis compilées en .class.
Pour les Web Service Soap, avec les fichiers XSD et WSDL, ce sont xjc et wsimport qui génèrent des classes java et .class à partir du XML. Il y a aussi des bascules entre JSON et sjava.
Enfin, il y a tout ce que l'on pourrait générer via de la génération de code maison avec du velocity et du freemarker. Le pire, c'est que ce code généré est très souvent ignoré dans les analyses de code statique de type Sonar, alors que la qualité du code généré ne lui permet pas toujours d'être optimisé par le compilateur JIT.
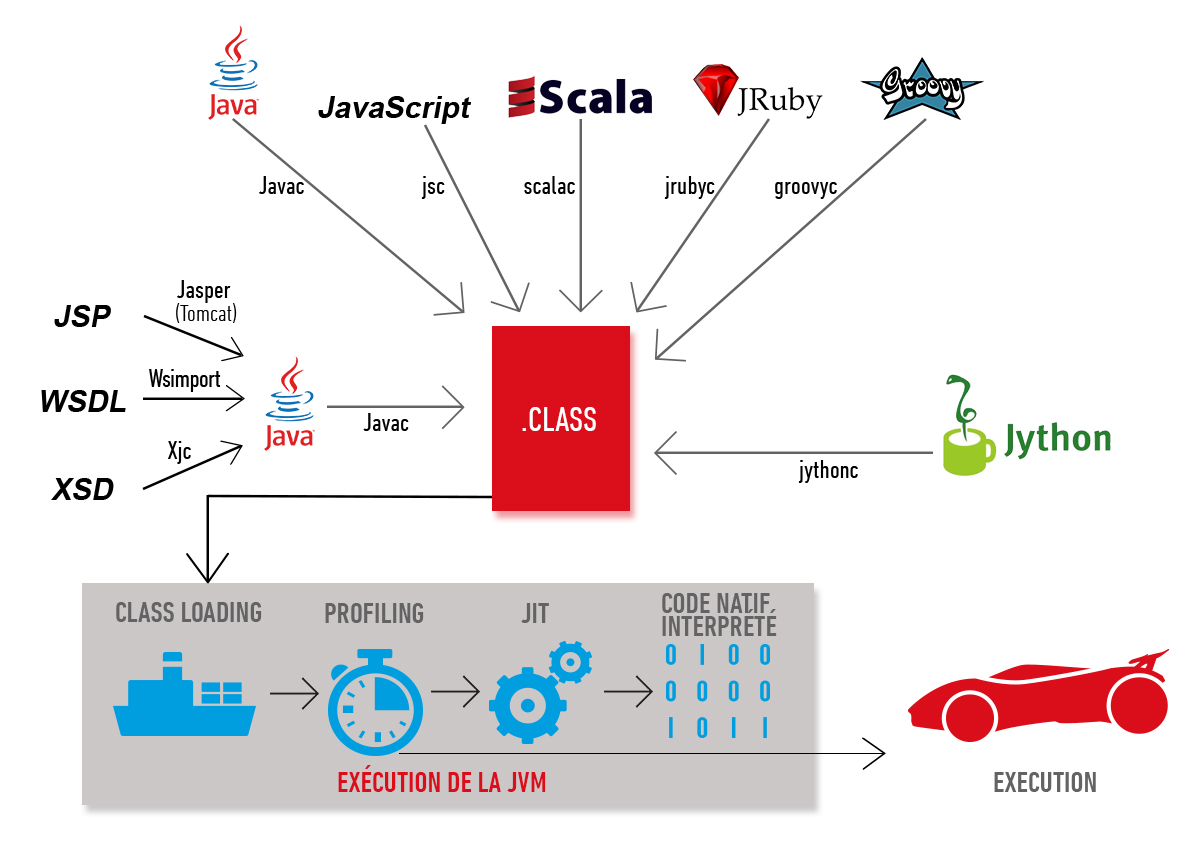
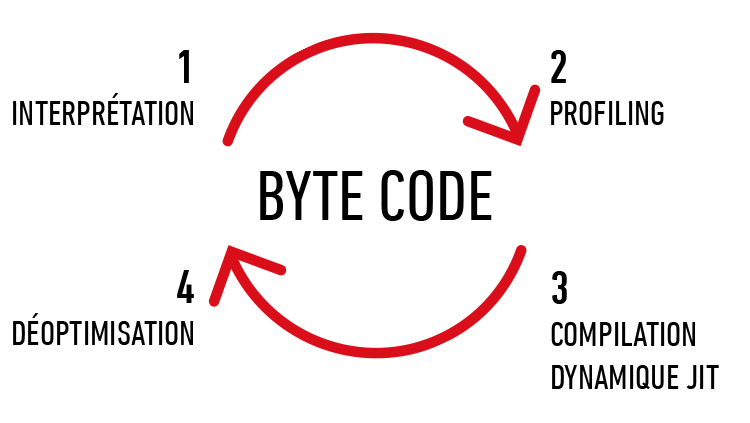
À la compilation en bytecode, aucune optimisation particulière n'est effectuée. C'est au moment de l'exécution qu'une optimisation dynamique sera effectuée sur les classes et les méthodes en ayant le plus besoin. Au début du lancement de la JVM, toutes les méthodes sont interprétées jusqu'à ce qu'un seuil en nombre d'exécutions soit atteint, et à condition que le code de la méthode à compiler ne soit pas trop long. C'est là qu'intervient le compilateur JIT (Just In Time) qui compile en assembleur, pour le processeur hôte (x86 ou x64 pour Intel), les instructions de bytecode.
Sur Android, le passage du mode interprété à un compilateur JIT a vu aussi une amélioration de performance, qui selon les benchmarks, passait sur le même appareil d'un facteur de 6 à 600, selon les tests dont en voici un sur le Nexus One (2010) lors du passage d'Android 2.1 à 2.2.
Sur les navigateurs Internet, ce compilateur JIT est également en place depuis quelques années pour que le code JavaScript soit lui aussi traduit en code assembleur. Firefox utilise le moteur IonMonkey qui possède un compilateur JIT, quant à Chrome avec le moteur V8, il utilise un autre moyen, la compilation dite “Ahead Of Time” (AoT) où toutes les classes JavaScript sont compilées en assembleur à leur première exécution.
Ce type de compilation AoT est également possible avec la JVM Oracle avec l'option -Xcomp. Cependant, nous y reviendrons plus tard, cela ajoute un temps de démarrage plus long et des optimisations précoces.
D'autres options sont possibles au lancement de la JVM :
- -Xint : pour un mode totalement interprété sans aucune traduction en assembleur par le JIT ;
- -Xmixed : qui est un compromis entre le tout compilé et le tout interprété. C'est aussi le mode par défaut de lancement de la JVM.
À noter que sur Android 4.4 (Kitkat), un nouveau mode d'exécution Java est disponible (mais non activé par défaut) : ART en remplacement de la JVM Dalvik. Ce que fait ART est une compilation Ahead Of Time au moment de l'installation de l'application.
II-B. Les types d'optimisations disponibles de la JVM▲
Afin d'optimiser au mieux le code interprété (puis compilé en assembleur), la JVM a besoin d'obtenir des métriques sur les méthodes et ainsi de faire un profiling sur l'ensemble des méthodes des classes chargées.
Voici un aperçu avec neuf types d'optimisations différentes parmi plus de 64 proposés par la JVM de Java 7 :
- Inlining : c'est la fusion du code d'une méthode appelante avec le code de la méthode appelée. Il en existe quatre types différents, mais le plus courant est le “monomorphic inlining”, ex. System.currentTimeMillis() lors d'appel de méthodes statiques ;
- Escape analysis : analyse le code en profondeur et lorsque c'est possible, évite de créer des instances d'objets lorsque celles-ci pointent sur des valeurs qui ne bougent pas, et remplace l'expression par l'utilisation d'une constante ;
- CHA Class Hierarchy Analysis (analyse des héritages et du polymorphisme qui permet de dévirtualiser) : en cas de besoin de dévirtualiser une méthode polymorphe héritée. Cela permettra d'utiliser de l'inlining sur cette méthode ;
- Optimisation CPU x64, MMX, SSE : ajout dans le code assembleur des instructions x64 sur processeur 64 bits, et des optimisations MMX et SSE pour les calculs sur les types « float » et « double », et également la recopie de tableaux ⇒ après divers essais, SSE et MMX accélère surtout les JVM 32 bits, car cela leur met à disposition des registres 64 bits, alors qu'en passant à des JVM 64 bits, l'accélération est moins visible ;
- Loop unrolling : lorsqu'une boucle s'effectue sur peu d'éléments et de manière constante, l'optimiseur remplace la boucle par n-fois le corps de cette boucle ;
- Lock coarsening : lors d'une boucle où une méthode synchronisée est appelée n-fois (avec le mécanisme de verrou aussi appelé n-fois), l'optimiseur replace les “n synchronized” par un seul avant la boucle principale, ce qui optimise les ressources de verrous ;
- Lock eliding : élimine un bloc “synchronized” lorsque celui-ci n'est pas nécessaire ;
- Dead code elimination : élimination du code mort (ex. condition irréalisable) ;
- Duplication code elimination : suite à une première optimisation, simplification du code optimisé.
La JVM a deux types de stratégies correspondant à deux compilateurs JIT différents :
- Démarrage rapide et optimisation moyenne : c'est le mode -client ou Compilateur C1 ;
- Profiling plus long des méthodes, mais meilleure optimisation : c'est le mode -server ou Compilateur C2.
Sur le JDK Oracle, un nouveau mode a fait son apparition depuis Java 6, c'est le mode Tiered (nivelé en français). Il tente de regrouper les qualités des deux compilateurs C1 (-client) et C2 (-server). Après des benchmarks, les résultats que j'ai obtenus ne sont pas assez probants. On peut jouer sur les paramètres suivants : -XX:+TieredCompilation ; seul ou en ajoutant -XX:TieredStopAtLevel=1 (jusqu'à 4 qui est la valeur par défaut).
Autre type de compilation : l'OSR (On Stack Remplacement). C'est une compilation à la volée lors d'une boucle sur une méthode encore en bytecode avec un nombre élevé d'itérations. C'est le cœur de la méthode qui est alors transformé en code assembleur juste pour l'exécution en cours. C'est une compilation “éphémère”, mais qui peut accélérer des boucles répétées un nombre de fois très élevé.
Sinon, alors que côté Microsoft et sa CLR, il a fallu attendre le framework dotNet 4.5 pour avoir la compilation assembleur en tâche de fond, celle-ci est disponible par défaut depuis Java 5.
Un dernier moyen d'optimiser le temps de lancement de la JVM et de la compilation est d'avoir déjà sous la main le code assembleur des classes du noyau (RT) de la JVM, c'est ce que fait le JDK Sun, puis Oracle depuis la version 5 via l'utilisation des classes JSA. Par défaut, le système tente de les utiliser et continue à fonctionner s'il ne parvient pas à les utiliser (l'activation se fait par -Xshare:dump ou -Xshare:on).
La JVM IBM j9 utilise aussi un moyen équivalent via l'option de démarrage -Xshareclasses.
Avec Java 8, est prévu également le multitenant dont le but est de centraliser les classes communes entre applications tournant dans la JVM et aussi de n'avoir qu'une seule copie des méthodes transformées en assembleur par le JIT, et ainsi économiser du temps de compilation et de la mémoire. Cependant l‘utilisation de debug, de profiling et d'agent (instrumentation) est problématique dans ce mode.
À noter que dans le monde des machines virtuelles, Microsoft avec la CLR a aussi de la compilation “AoT” via l'outil ngen qui propose une version du bytecode dotNet (IL), compilée en assembleur, mais sans profiling et donc avec une optimisation moindre.
Une autre solution proposée par Microsoft n'existe pas encore dans la JVM est MPOG : Managed Profiled Guided Optimization, dont le but est de réconcilier les deux mondes JIT et AoT via la création d'un profiling JIT pendant l'exécution de l'application, puis une compilation “Ahead Of Time” prenant en compte les informations de profiling lors de la phase précédente. Le gain de performance pourrait être de 25 % par rapport à du “simple” AoT via ngen.
Ici s'arrête le 1er article de cette série sur les optimisations de la JVM. Le second article traitera des options permettant de constater toutes les compilations JIT.
III. Le monitoring de la compilation dynamique▲
La compilation du bytecode en code assembleur est effectuée sur des portions de méthodes ou sur des méthodes entières, si elles sont assez courtes et appelées très souvent.
Cette compilation prend du temps (ce qui peut être tracé) et de la place mémoire (qui peut également être tracé).
Sur la JVM Oracle (et OpenJDK), il est possible d'afficher les temps de compilation et la taille du code compilé qui dépendent du compilateur C1, C2 ou Tiered (C1+C2).
L'option à ajouter au démarrage « -XX:+CITime »
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
Informations du -XX:+CITime avec le compilateur C1 (-client)
Accumulated compiler times (for compiled methods only)
————————————————
Total compilation time : 0.684 sStandard compilation : 0.287 s, Average : 0.008On stack replacement : 0.397 s, Average : 0.011Detailed C1 TimingsSetup time: 0.000 s ( 0.0%)Build IR: 0.392 s (57.6%)
Optimize: 0.006 s ( 0.8%)
Emit LIR: 0.244 s (35.8%)
LIR Gen: 0.111 s (16.3%)
Linear Scan: 0.132 s (19.4%)
LIR Schedule: 0.000 s ( 0.0%)
Code Emission: 0.038 s ( 5.6%)
Code Installation: 0.006 s ( 0.9%)
Instruction Nodes: 217463 nodes
Total compiled bytecodes : 377139 bytes
Standard compilation : 147744 bytes
On stack replacement : 229395 bytes
Average compilation speed: 551622 bytes/s
nmethod code size : 1375616 bytes
nmethod total size : 4064232 bytes
Informations du -XX:+CITime avec le compilateur C2 (-server)
Accumulated compiler times (for compiled methods only)
————————————————
Total compilation time : 8.833 sStandard compilation : 6.453 s, Average : 0.208On stack replacement : 2.381 s, Average : 0.077Total compiled bytecodes : 175772 bytesStandard compilation : 98127 bytesOn stack replacement : 77645 bytes
Average compilation speed: 19898 bytes/s
nmethod code size : 374432 bytes
nmethod total size : 1469764 bytes
Pour obtenir des informations sur la compilation JIT, il faut utiliser l'option de la JVM suivante : -XX:+PrintCompilation
À noter que plus la version mineure du JDK augmente, plus les informations tracées sont précises.
Exemple :
2.
3.
4.
5.
6.
7.
8.
9.
36 1 3 java.lang.Object::<init> (1 bytes)
37 2 1 java.lang.reflect.Field::getName (5 bytes)
37 3 3 java.lang.Number::<init> (5 bytes)
39 1 3 java.lang.Object::<init> (1 bytes) made not entrant
40 7 1 java.lang.reflect.Method::getName (5 bytes)
41 9 n 0 java.lang.invoke.MethodHandle::linkToStatic(LL)L (native) (static)
91 54 s 3 java.io.ByteArrayInputStream::read (36 bytes)
95 62 ! 3 java.io.BufferedReader::readLine (304 bytes)
188 166 % 3 fib_nc::_c1 @ 106 (157 bytes)
Explications :
- première colonne = temps en ms depuis le début du lancement de la JVM ;
- deuxième colonne = n° d'ordre des méthodes compilées ;
- quatrième colonne = que des chiffres de 0 à 4 ; correspond au niveau de compilation (0 =native, 1 à 3 = C1, 4 = C2 -server) ;
- ! = code contenant des exceptions (qui elles aussi sont compilées) ;
- n = native ;
- s= synchronized :
- % → compilation de la méthode à la volée ( OSR ) ; sur le libellé “188 166 % 3 fib_nc::_c1 @ 106 (157 bytes)”, le @106 indique l'offset à partir duquel la méthode OSR a été compilée ;
- made zombie = méthode désoptimisée (en général en attente d'exceptions éventuelles) ;
- made not entrant = compilée une fois, mais on ne peut plus lui faire appel (en général en attente d'exceptions éventuelles) ;
- uncommon trap = changement intervenu sur la méthode (ex. instrumentation JVMTI).
Il est possible d'avoir des informations aussi sur l'inlining et le temps de compilation de cette méthode précise en ajoutant : -XX:+UnlockDiagnosticVMOptions -XX:+PrintCompilation2.
2.
3.
4.
5.
6.
7.
448 101 4 sqli.examples.TestHugeMethodv6::tresGrosseMethode17643opcode (17643 bytes)
3069 101 4 sqli.examples.TestHugeMethodv6::tresGrosseMethode17643opcode (17643 bytes) COMPILE SKIPPED: out of nodes before split (retry at different tier)
3069 101 time: 2621 inlined: 0 bytes
119 71 3 java.util.HashMap::get (23 bytes)
119 71 size: 1392(928) time: 0 inlined: 20 bytesPour l'OSR :
80697 141 % 3 sqli.examples.TestHugeMethodv6::doMainLoops @ 717 (1422 bytes)
80715 141 % size: 180688(104960) time: 17 inlined: 4371 bytes
L'inlining peut procurer un gain de temps de traitement important. Il est utile d'analyser son utilisation par la JVM via les deux options suivantes : -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining.
Exemple :
2.
3.
4.
5.
6.
@ 1 java.lang.Object::<init> (1 bytes)
@ 1 java.lang.Number::<init> (5 bytes)
@ 66 java.lang.String::indexOfSupplementary (71 bytes) too big
@ 14 sun.misc.Unsafe::getObjectVolatile (0 bytes) intrinsic
@ 3 java.lang.String::indexOf (70 bytes) callee is too large
@ 15 java.lang.Double::<init> (10 bytes) inline (hot)
Explications :
- la première colonne avec le "@" indique l'offset (en bytecode) de la méthode où on a mis en place l'inlining ;
- dans l'exemple ci-dessus, avec « @ 3 java.lang.String::indexOf » puis la ligne en dessous décalée @15, cela veut dire que l'on a fait un inlining sur deux méthodes et qu'elles ont été fusionnées ensemble ;
- inline (hot) : c'est quand une méthode ne dépasse pas les 35 octets de bytecode ;
- Intrinsic : remplacement du bytecode par le code natif de la fonction (ex. pour les System.arrayCopy, les String.equals, la plupart des fonctions mathématiques) ;
- too big : méthode trop grande pour profiter d'un inlining ;
- callee is too large : la méthode appelée est trop grande pour fusionner les deux méthodes appelante / appelée.
Globalement, en JDK 1.8 pour l'option -XX:+PrintInlining, les explications sont plus nombreuses et axées sur la non-réussite de l'inlining. En JDK 1.7, on indiquait plutôt les méthodes ayant réussi leur inlining et assez peu les cas d'échecs.
Pour les plus curieux, voir ci-dessous l'option le code assembleur généré.
Le code assembleur généré apparaît grâce aux options suivantes :
-XX:+UnlockDiagnosticVMOptions et -XX:+PrintAssembly -XX:+DebugNonSafepoints
Il faut par contre ajouter une DLL dans le répertoire bin du JDK (hsdis-i386.dll pour un JDK 32 bits).
Exemple de résultat :
2.
3.
4.
5.
6.
7.
8.
0x02495e8a: adc ,0x3a8() ;
*invokevirtual doubleValue;
- TestHugeMethod::moyenneMethode@1387 (line 1110)0x02495e90: mov $0x347e0778, ;
{oop(" 445 ")}0x02495e95: xchg %ax,%ax0x02495e97: call 0x0242d700 ;
OopMap{ebp=Oop off=4316};
*invokestatic valueOf;
- TestHugeMethod::moyenneMethode@1396 (line 1110);
{static_call}
Pour les autres JVM, côté IBM, il y a l'option -Xaot:verbose et -Xjit:verbose.
Pour Jrockit, il y a l'option -Xverbose ou en plus complet : -Xverbose:opts,gen
IV. Les limites de l'optimisation▲
Nombre d'exécutions d'une boucle avant compilation JIT :
- au bout de 1500 en mode -client ;
- au bout de 10 000 en mode -server.
Pour changer ce nombre côté Oracle, il faut ajouter l'option suivante au démarrage :
-XX:CompileThreshold=xxx
Pour IBM, c'est -Xjit:count=xxxx et -Xaot:count=xxxx
Taille maximum du code source d'une méthode :
- 64 ko de code source pour la taille d'une seule méthode (ce chiffre pour une seule méthode peut paraître ridicule, mais les compilateurs comme JSC de Rhino peuvent produire un code source Java supérieur à 65 ko sur une seule méthode, selon la taille du fichier JavaScript à compiler).
Taille maximum en bytecode d'une méthode :
- 8 ko de bytecode : seuil de la JVM Oracle à ne pas dépasser, sinon il n'y a pas de compilation, on reste en interprété ⇒ contournable par l'option -XX:-DontCompileHugeMethods en Oracle ou passer à IBM Java 7 (qui n'a pas de limite de taille) :
- 4870 octets de bytecode : seuil de la JVM 1.6 d'IBM où toute méthode en dessous de cette taille a un gain significatif (jusqu'à 10 fois) de la vitesse d'exécution ;
- 4 ko de bytecode : seuil de la JVM JRockit en dessous duquel la vitesse est significativement plus élevée ;
- 2 ko de bytecode : seuil en dessous duquel que j'ai constaté sur la JVM 1.7 d'Oracle que toute méthode répond beaucoup plus vite que dans l'intervalle ]2 ko, 8 ko[ ;
- 1000 octets de bytecode : seuil au-delà duquel il n'y a pas d'inlining direct de la méthode (seulement une partielle) ⇒ Contournable par l'option -XX:InlineSmallCode=xxxx ;
- 35 octets de bytecode : seuil au-delà duquel il n'y a pas de full inlining ⇒ contournable par l'option -XX:MaxInlineSize=xxxx.
V. Un outil minimaliste pour calculer la taille des méthodes d'une classe▲
Pour déterminer si on dépasse un seuil important 8 ko, 4 ko, 1 ko ou 35 octets de bytecode, on a l'outil de base via javap (du JDK) qui permet de décompiler un fichier .class et de connaître la taille de chaque méthode au prix d'une analyse non intuitive.
Exemple avec javap -c MaClasseXxx.class
public static void loopFib(long);Code:0: lconst_0…16: lstore_217: goto 220: return
Ici, la dernière ligne de cette méthode contient “20”, c'est la taille en bytecode de la méthode.
Voici l'outil minimaliste qui permet d'analyser la taille des méthodes potentiellement lors de l'intégration continue. Pour rester concis, cet article ne contient que le squelette de code pour scruter une classe entière en se basant sur l'api ASM pour l'analyse du bytecode.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
import org.objectweb.asm.ClassReader;
import org.objectweb.asm.MethodVisitor;
import org.objectweb.asm.Opcodes;
import org.objectweb.asm.Type;
import org.objectweb.asm.commons.CodeSizeEvaluator;
import org.objectweb.asm.tree.AbstractInsnNode;
import org.objectweb.asm.tree.ClassNode;
import org.objectweb.asm.tree.MethodNode;
import org.objectweb.asm.tree.analysis.Frame;
...
File maClasse = new File("MaclasseDeTest.class");
ClassReader cr = new ClassReader(new FileInputStream(maClasse));
ClassNode cn = new ClassNode();
cr.accept(cn, ClassReader.SKIP_DEBUG);
List<MethodNode> methods = cn.methods;
for (int i = 0; i < methods.size(); ++i) {
MethodNode method = methods.get(i);
if (method.instructions.size() > 0) {
try {
MethodNode m1 = new MethodNode();
m1.access = method.access;
m1.tryCatchBlocks = method.tryCatchBlocks;
CodeSizeEvaluator mv2 = new CodeSizeEvaluator(m1);
method.accept(mv2);
int tailleByteCode = mv2.getMinSize();
// TODO faire quelque chose avec la taille
// trouvée en bytecode de la méthode...
} catch (Exception e) {
log.error(e);
}
}
} // fin du FOR chq méthode
Avec ce squelette de programme, vous allez pouvoir vérifier plus facilement la taille des méthodes en bytecode. Dans le prochaine partie, nous verrons, au travers de trois types de tests, le comportement de la JVM face à la taille des méthodes et des JVM respectives.
VI. Tests : relation entre la taille des méthodes et le comportement de la JVM▲
Cet article est le dernier de la série sur la Java Virtual Machine qui présente les différents résultats en termes de taille de méthode et de vitesse d'exécution avec au moins 6 JDK différents. Le but est de montrer l'influence de la taille des méthodes sur la compilation JIT et la vitesse de traitement.
VI-A. Test sur l'influence de la taille des méthodes▲
Voici un test contenant de mauvaises pratiques sur la taille des méthodes. Le code possède volontairement une initialisation de tableau très longue (remplie de « Double.valueOf("445"),.. ») dans les méthodes à tester.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
public static void tresGrosseMethode17643opcode() {
double[] testBidon = new double[] {
Double.valueOf("445"), Double.valueOf("445"),..
};
double sum = 0.0d;
final int taille = 100;
for (int i = 0; i < 10000; i++) {
for (int idx = 0; idx < taille; idx++) {
sum += testBidon[idx];
sum /= 1.00001d;
}
}
}
Bilan sur le test de vitesse d'exécution selon la taille des méthodes.
- Plus les JVM sont récentes (java 7 et +), plus le gain en réduisant la taille des méthodes est perceptible.
- La taille idéale d'une méthode semble être vers les 80 à 300 octets de bytecode, ce qui est difficilement traduisible en nombre de lignes, mais disons autour des 20 à 30 lignes de code. Cependant, sans JVM java 7 ou 8 en -server, aucune amélioration de vitesse ne sera constatable.
- Le découpage à l'extrême des méthodes en sous-méthodes plus petites peut donner de mauvais résultats surtout avant compilation et optimisation globale de l'ensemble. Après une phase de "warm up" et lorsque la JVM le permet, les temps de réponse sont optimisés.
- Oracle Java 6 aussi bien 32 bits que 64 bits n'arrive pas à optimiser des méthodes de taille intermédiaire (entre 1 et 7999 octets de bytecode)
- L'option « -XX:DesiredLimitMethod=xxxx » activable uniquement en JDK 1.6 n'a aucune influence directe sur la rapidité d'exécution des méthodes contrairement à ce que l'option laisse supposer.
- Pour Oracle Java 7, entre la version -client et -server, il y a une différence de vitesse de 770 en faveur du mode -server. De même, Java 7 (en mode -server) a des performances bien meilleures que Java 6.
- Sur la JVM Oracle, les paramètres de tuning de l'inlining suivant semblent inefficaces : -XX:-ClipInlining, -XX:InlineSmallCode=xxx et -XX:MaxInlineSize=xxx et n'ont aucune influence directe.
- De même, l'inlining s'arrête lorsque la limite de « DesiredLimitMethod » (8 ko) de bytecode est atteinte. La JVM parle de « clipping » de l'inlining. En conséquence, si les méthodes fusionnées arrivent au total à moins de 8 ko, elles seront plus rapides que lorsqu'on a atteint la limite des 8 ko et qu'aucun inlining ne peut plus arriver en fin de méthode appelante.
- Depuis la version 7 (et supérieure), le paramètre « DesiredLimitMethod ) est en dur dans globals.hpp du code source du JDK (voir ligne 3553).
- Les options de compilation « -XX :TieredCompilation » et « -XX :TieredStopAtLevel=1 à 4 » sont dépendantes du -client ou -server. Globalement les performances sont meilleures avec le niveau 4 (qui est la valeur par défaut).
- Sur la JVM java 7 d'Oracle, une amélioration de vitesse se fait sentir lorsque celle-ci est en dessous du seuil de 2 ko de bytecode (jusqu'à 3 à 4 fois plus rapide par rapport à des méthodes comprises entre 2 ko et 8 ko) et encore plus vers 300 à 80 octets de bytecode.
- Sur la JVM 1.6 d'IBM (J9) en 32 bits, dès que la taille d'une méthode arrive en dessous du seuil de 4870 octets de bytecode, la méthode voit sa vitesse s'améliorer d'un facteur 54 minimum (268 fois après un "warm up" sur le test effectué).
- Sur la JVM 1.6 d'IBM (J9), le "warm up" d'une méthode fortement découpée peut être lent, mais une fois en place, la méthode peut être jusqu'à plus de 1000 fois plus rapide que si la méthode dépasse 4870 octets de bytecode.
- Sur la JVM IBM en java 7 64 bits, il n'y a pas de limitation de taille sur les méthodes à compiler en code assembleur. Les méthodes sont plus rapides qu'en Java 6 IBM. De même que pour Java 7 Oracle (en -server), en dessous de 2 ko de bytecode, les méthodes sont encore plus rapides.
- La JVM Jrockit Java 6 32 bits a également un seuil à 4 ko de bytecode ou, lorsqu'une méthode est en dessous de quelques octets de code, elle voit sa vitesse augmenter par 10 minimum.
VI-B. Test sur l'influence de la taille des méthodes appelantes et appelées sur l'inlining▲
Voici un autre test pour vérifier la réaction de l'inlining lors de fusion entre de grandes méthodes appelées ou appelantes avec des petites méthodes appelantes ou appelées.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
public static void step1_grandCallerNotInline1165opcode() {
double[] tmp = new double[] {
Double.valueOf("445"),
Double.valueOf("445"),
Double.valueOf("445"),
Double.valueOf("445"), ... Encore beaucoup ...
};
double[] testBidon = Arrays.copyOf(tmp , 100 );
for (int i = tmp.length; i < 100; i++) {
testBidon[i] = Double.valueOf("445");
}
step1_petitCalleeNotInline52opcode(testBidon);
}
public static void step1_petitCalleeNotInline52opcode(double[] testBidon) {
double sum = 0.0d;
final int taille = 100;
for (int i = 0; i < 10000; i++) {
for (int idx = 0; idx < taille; idx++) {
sum += testBidon[idx];
sum /= 1.00001d;
}
}
}
Bilan sur le test de vitesse d'exécution selon la taille des méthodes appelantes et appelées :
- indépendamment des versions de JDK, si la taille de la méthode appelée ou appelante devient trop grande, la vitesse est moindre ;
- sur l'ensemble des tests sur les JVM, le résultat est plus homogène lorsqu'on utilise une méthode appelante plus petite que la méthode appelée ; celle-ci peut être plus grande ou de taille quasi équivalente à la première ;
- même avec plusieurs essais et une séance de "warm up", les résultats sont parfois surprenants, il est donc peu évident de tirer des conclusions définitives ;
- en général, les JDK 32 bits (6 et 7) en mode -client sont incapables d'accélérer les petites méthodes appelées ou appelantes.
VI-C. Test sur l'influence de méthode courte et du Full Inlining▲
Le dernier test consiste à vérifier le comportement de la JVM lorsque les méthodes sont suffisamment courtes (environ moins de six lignes de code). En effet, les méthodes ne dépassant pas 35 octets de bytecode de code sont éligibles à un « Full Inlining » qui est une fusion directe des méthodes appelées et appelantes. L'idée du test est de vérifier le comportement de la JVM, sa capacité à fusionner plusieurs petites méthodes et l'influence des paramètres lors des appels de méthodes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
private static double[] step1_fullInlinableCreate2Values_Test1() {
return new double[] {
Double.valueOf("445"), Double.valueOf("445")
};
}
private static void step1_fullInlinedFillArrayInLoop_Test1(final int nbElementsCrees,double[] testBidon, int i) {
double[] tmpArray = step1_fullInlinableCreate2Values_Test1();
for (int idx=0; idx < nbElementsCrees; idx++) {
testBidon[(i*nbElementsCrees)+idx] = tmpArray[idx];
}
}
/**
* Test inlining avec le corps de la méthode dans la boucle + plusieurs paramètres en E/S.
*/
public static void step1_methodeAvecTresPetitInlining_Test1() {
final int nbElementsCrees = step1_fullInlinableCreate2Values_Test1().length;
final int maxElements = 4200; // supérieur à 8000
double[] testBidon = new double[maxElements*nbElementsCrees];
for (int i = 0; i < maxElements; i++) {
step1_fullInlinedFillArrayInLoop_Test1(nbElementsCrees, testBidon, i);
}
double sum = 0.0d;
final int taille = 100;
for (int i = 0; i < 10000; i++) {
for (int idx = 0; idx < taille; idx++) {
sum += testBidon[idx];
sum /= 1.00001d;
}
}
}
Bilan sur le test de vitesse d'exécution selon la taille des méthodes appelantes et appelées.
- De manière générale, à trop découper les méthodes dans lesquelles on a des "for" imbriqués, on a des contre-performances. Exemple : une méthode de 30 lignes découpées en cinq méthodes de six lignes. On arrive aux limites de l'inlining des JVM actuelles et c'est finalement au moins 20 fois plus lent que des méthodes de taille intermédiaire d'environ 20 à 30 lignes de code.
- Plus on prend une version récente du JDK, plus c'est optimisé pour les petites tailles de méthodes.
- Il y a peu de différences dans l'appel des méthodes si la boucle "for" est en dehors ou à l'intérieur de la méthode appelée.
- Il y a peu de différences si l'appel d'une méthode utilise le passage par plusieurs paramètres ou le passage d'une référence de type databean. Sauf pour le JDK 7 et 8 en 64 bits où, après "warm up", l'utilisation d'un databean ou d'attributs privés semble être meilleurs que l'envoi de tableau en paramètre.
Bilan sur l'ensemble des trois tests.
- Les options Oracle qui marchent (mais à ne pas désactiver) : désactivation de l'OSR (-XX:-UseOnStackReplacement), désactivation d'une partie de l'inlining (-XX:-Inline), désactivation de l'Escape Analysis (-XX :-DoEscapeAnalysis).
- Sur la JVM Oracle, l'option -XX:+TieredCompilation ne réagit pas pareil lorsqu'on force -client ou -server. Dans la majorité des tests, les résultats sont meilleurs avec -server .
- La compilation AoT (via -Xcomp ou IBM -Xjit:count=0) n'est pas la meilleure idée pour de bonnes performances, car toutes les méthodes sont compilées à la 1re exécution. Il faut un temps de "warm up" beaucoup plus long pour des applications lancées avec cette option. L'option par défaut « -Xmixed » reste le meilleur compromis.
- Si vous travaillez sur une JVM en OS virtualisé, vérifiez bien que le mode SSE4 et 4.2 du CPU sont activés, le risque est de perdre en temps de réponse lors de calculs intensifs.
- Le paramètre pour changer le seuil de 1 ko pour l'inlining semble ne pas fonctionner ou être inefficace, car il n'y a aucun changement notable quand on le change
- La JVM a besoin d'un “warm up” pour tirer parti de sa quintessence. C'est à prendre en compte pour des tests de performance Web ou batch et également pour des "micro-benchmarks".
Pour information, en pièce jointe, se trouvent le code source des classes de tests. Je n'ai pas cherché à le rendre "beau", mais j'y ai mis l'essentiel pour les tests à effectuer.
VII. Conclusion générale sur l'optimisation de la JVM▲
Le sujet est vaste et finalement très peu connu et étudié. En effet, c'est d'abord le paramétrage du Garbage Collector et de la mémoire qui seront les premiers facteurs d'accélération d'une application fonctionnant sur la JVM.
Dans la majorité des cas, une réduction de la taille de la méthode en la descendant jusqu'à 20 à 30 lignes de code va apporter un gain de vitesse notable sur Java 7 et supérieur. Cependant, pour que l'application soit elle-même plus rapide, il faut que la méthode réécrite soit réellement appelée souvent et soit un goulet d'étranglement pour le reste de l'application.
Après avoir modifié le code source de quelques projets Open Source (base de données H2 et Derby ainsi que d'autres projets) en ayant découpé quelques grosses méthodes en blocs plus fins, des gains ont été perçus, mais pas assez significatifs. Était-ce aussi que les tests sur des bases de données mémoires étaient quand même fortement liés aux entrées/sorties ? Je compte poursuivre d'autres tests sur des projets moins dépendants des I/O.
Toujours est-il qu'il faut se méfier du code produit par des générateurs de code Java ou de bytecode. Autant le compilateur scalac crée des petites classes et des petites méthodes, autant les jrubyc et le compilateur jsc de Rhino, créent sans option une grosse méthode comportant l'ensemble du programme à exécuter : la méthode principale peut vite dépasser le seuil de 2 ko de bytecode et se retrouver beaucoup plus lente que si le code généré était mieux découpé.
Ce constat est le même pour les JSP qui peuvent vite se retrouver avec une méthode _jspService() très grosse. Cependant les JSP ne produisent en général qu'un ajout de chaînes de caractères dans un buffer, et même l'interprétation de cela reste encore rapide. Selon, les tests effectués, la JVM utilisait moins de CPU sur des JSP dont la taille était "optimisée pour une compilation assembleur, mais les temps de réponse globaux étaient les mêmes qu'avec des JSP plus grosses.
VIII. Remerciements▲
Cet article a été publié avec l'aimable autorisation de SQLI qui est le partenaire de référence des entreprises dans la définition, la mise en œuvre et le pilotage de leur transformation digitale.
Nous tenons à remercier Jacques Jean pour la relecture orthographique, puis milkoseck et Mickael Baron pour la mise au gabarit.