



I. Introduction▲

Devant l'étendue des possibilités qu'offrent Apache Mahout et de ses divers packages, j'ai choisi de me concentrer sur les applications possibles dans le domaine du e-commerce en complément de solutions comme Magento ou hybris.
Dans une première partie, nous aborderons plus spécifiquement les recommandations pour conclure, et, dans une seconde partie, sur les usages détournés de Apache Mahout en corrélation avec les réseaux sociaux comme Twitter ou Facebook.
II. APACHE MAHOUT : machine learning▲
Apache Mahout est une bibliothèque Java regroupant un ensemble d'algorithmes mathématiques à usage général. Toutes les implémentations ont été faites afin d'être aisément scalables sur Apache Hadoop, la plupart des algorithmes étant applicables à Map-Reduce.
Les algorithmes intégrés permettant de traiter des problématiques de clustering, de classification et d'apprentissage automatique dont les utilisations peuvent être aussi diverses que les études probabilistes, l'analyse de comportements, le recoupement d'informations, ou juste les suggestions d'articles similaires sur LeMonde.fr (ça serait un peu « overkill » vous me direz).
Mahout contient également un certain nombre d'utilitaires pour s'adapter à divers formats de données et plateformes de stockage, et peut même exploiter directement Apache Lucene pour l'analyse textuelle.
III. MAHOUT TASTE et les algorithmes de recommandation▲
Ce qui nous intéresse tout particulièrement dans Mahout, c'est le package Taste, qui permet de faire de la recommandation. De la recommandation de quoi ? Eh bien de ce qu'on veut, tant que c'est identifié par une valeur numérique.
Mahout Taste traite basiquement deux types d'entités : les utilisateurs et les objets (mais ce n'est qu'une terminologie puisque ce ne sont que des identifiants). Il consomme en fait un ensemble de préférences utilisateur->objet.
Ces préférences peuvent être numériques :
- l'utilisateur #1 a attribué la note 5 à l'objet #42 ;
- l'utilisateur #2 a attribué la note 3 à l'objet #1337 ;
mais elles peuvent aussi être booléennes :
- l'utilisateur #3 aime l'objet #22 ;
- l'utilisateur #4 aime l'objet #23.
Toutes ces préférences sont regroupées dans ce qu'on appelle un DataModel, qui est utilisé pour calculer divers jeux de données :
- ItemSimilarity tableau indiquant la similarité (entre -1.0 et 1.0) entre chaque objet et tous les autres ;
- UserSimilarity même chose pour les utilisateurs ;
- UserNeighborhood groupe d'utilisateurs similaires entre eux.
Pour calculer ces similarités et voisinages, Mahout Taste utilise les autres algorithmes de la bibliothèque (c'est bien de la classification et du clustering que l'on fait ici !).
Enfin la dernière « couche » du package Taste c'est « les Recommender ». Un Recommender est un objet qui est capable, à partir d'un identifiant d'utilisateur connu, de recommander plusieurs objets en prenant en compte sa similarité avec les autres utilisateurs, et la similarité des objets qu'il a déjà préférés avec d'autres objets.
Un petit diagramme issu de la documentation officielle pour résumer tout ça ?
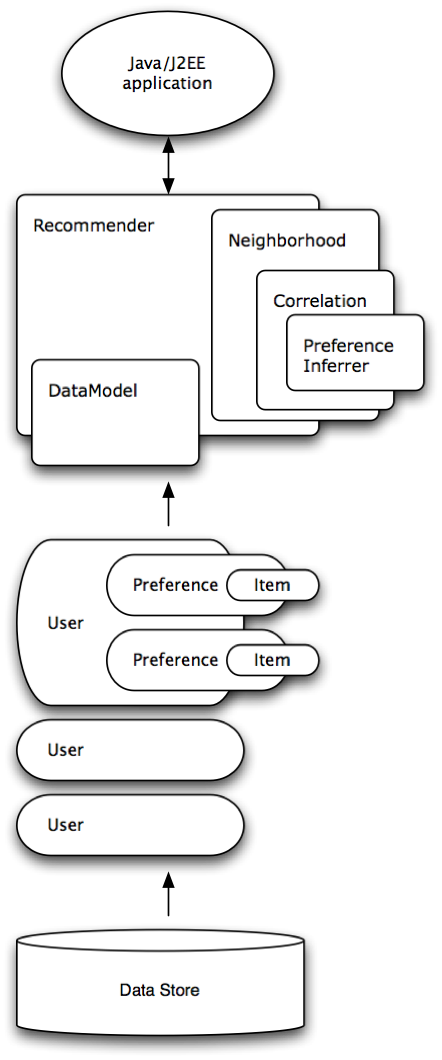
L'utilisation de ces objets est relativement simple, voici un exemple pour des recommandations basées sur la similarité entre utilisateurs :

IV. Une utilisation commerciale dans nos solutions B2B et B2C▲
En lisant cette courte description de l'algorithme de recommandation de Mahout, vous avez sûrement pensé à ce que font Amazon ou autre Fnac sur leur site web : promouvoir des produits qui pourraient intéresser l'utilisateur pour espérer augmenter le volume de ventes (et je peux dire, en tant qu'acheteur, que ça marche pas mal !).
Nous espérons donc utiliser Mahout Taste pour créer un module de recommandation personnalisée qui serait intégré à nos solutions Magento et hybris (principalement).
L'utilisation qui vient immédiatement à l'esprit est bien sûr la recommandation de produits similaires sur une page produit. Ce type de recommandation peut être fait uniquement à partir des métadonnées des produits (même catégorie, même marque, même modèle, etc.), mais la puissance de Mahout Taste permet d'apporter une dimension « humaine » à ces recommandations. C'est-à-dire prendre en compte les habitudes des utilisateurs pour pousser des produits plus pertinents et donc plus susceptibles d'être achetés.
D'autres cas tout aussi utiles peuvent être imaginés :
- proposer sur la page d'accueil des produits similaires aux anciens achats et anciennes visites de l'utilisateur ;
- proposer sur les pages panier et confirmation de commande des produits souvent achetés avec ceux qui s'y trouvent ;
- capitaliser sur les pages d'erreurs (404, recherche infructueuse) ;
- intégrer du contenu pertinent dans les newsletters personnalisées.
Nous allons voir maintenant les possibilités qui s'offrent à nous pour répondre aux exigences marketing et exploiter les données des réseaux sociaux.
V. L'interface IDRESCORER pour jouer avec les résultats▲
Sans surprise, l'utilisateur d'une solution de recommandations a pour objectif d'augmenter son volume de ventes. L'ajout de recommandations personnalisées (et j'insiste bien sur ce mot) y participe, mais c'est parfois insuffisant : quid des offres promotionnelles saisonnières, quid des effets de bord indésirables (recommandations non appropriées en fonction du contexte) et quid de la volonté de vendre, par exemple, surtout des produits à forte marge ?
IV-A. Présentation d'IDRESCORER▲
Heureusement pour nous, Mahout Taste n'est pas une boîte noire, il propose divers points d'inflexion assez simples à mettre en place sur l'algorithme… et si ce n'est pas suffisant, on peut toujours surclasser les objets !
Ce qui nous intéresse ici est l'interface IDRescorer
(org.apache.mahout.cf.taste.recommender.IDRescorer pour les intimes) qui est une toute petite interface avec seulement deux méthodes :
2.
3.
4.
public interface IDRescorer {
double rescore(long id, double originalScore);
boolean isFiltered(long id);
}
Une implémentation de IDRescorer est fournie à un Recommender au moment de la recommandation, en plus de l'identifiant utilisateur et du nombre de résultats désirés :
2.
List<RecommendedItem> recommendations = recommender.recommend(USER_ID,
5, customRescorer);
Quand un Recommender se voit fournir un rescorer, la méthode rescore() sera appelée pour chaque objet recommandé, après le calcul du score et avant le tri des résultats. Cela permet donc, selon une logique personnalisée, de modifier le score de certains produits.
La méthode isFiltered() permet quant à elle de totalement exclure un résultat (c'est également possible en retournant un Double.NaN dans rescore).
On voit bien que les données fournies au rescorer sont limitées, on ne sait même pas quel utilisateur demande une recommandation, il faudra donc prévoir dans notre implémentation de pouvoir récupérer cette info, en plus bien sûr, des nouveaux scores que l'on veut renvoyer.
IV-B. Constitution des scores▲
Parlons-en de ces nouveaux scores, comment les définir ? N'oublions pas que l'intérêt de cette solution par rapport à ce que l'on peut déjà trouver dans Magento et autre hybris est le peu de configuration nécessaire pour avoir un système fonctionnel : hors de question donc d'imposer au client de configurer manuellement pour chaque produit un multiplicateur de score !
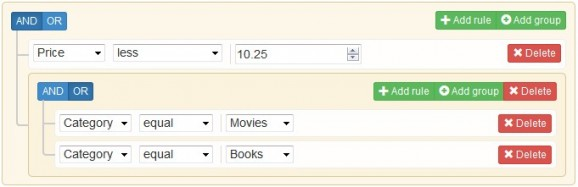
Une idée intéressante est celle des filtres de produits, basés sur les métadonnées de ces derniers et en appliquant le même multiplicateur pour tous les produits correspondants. On peut alors créer des règles plus ou moins complexes telles que :
- recommander en priorité les produits avec une marge de plus de 30 % ;
- moins recommander les produits ayant moins de 10 unités en stock ;
- recommander pendant les vacances d'été les produits qui se trouvent dans les catégories « Plage » et « Family packs » ;
- ne jamais recommander les films d'horreur sur la page d'accueil.
Pour créer de telles règles dans une optique d'interface web conviviale, on peut trouver des plugins jQuery tels que jui_filter_rules ou jQuery QueryBuilder, tous deux sous licence open source.
VI. La vague sociale▲
Les réseaux sociaux sont merveilleux. À condition que l'utilisateur nous en donne l'autorisation, on peut connaître certains détails personnels, ses centres d'intérêt, ses amis et sa famille, tout ceci à travers des WebServices très simples à utiliser. Par exemple pour Twitter et Facebook.
Deux utilisations de ces données peuvent être imaginées : connaître les liens entre plusieurs utilisateurs ou identifier des produits correspondants aux centres d'intérêt.
VI-A. Identification de groupes d'utilisateurs▲
Petit rappel, Mahout utilise des objets UserNeighborhood pour générer ses recommandations. De base, ils sont construits automatiquement en constituant des groupes d'utilisateurs qui consultent ou achètent les mêmes produits. Mais on peut aussi lui fournir des objets préconstruits avec des données bien à nous.
Quoi de plus simple alors que de récupérer les amis Facebook et les followers Twitter de notre utilisateur, voir lesquels sont déjà inscrits sur la plateforme de vente et demander à Mahout de créer un nouvel espace de recommandation avec ces données. L'avantage est double :
- les recommandations personnalisées seront encore plus précises puisque basées sur des proches ayant potentiellement les mêmes centres d'intérêt ;
- la possibilité de fournir des recommandations dès l'inscription de l'utilisateur sur le site alors même qu'il n'a encore consulté aucun produit.
VI-B. Analyse des centres d'intérêt▲
Je vais ici m'éloigner un peu de Mahout tout en restant dans la recommandation de produits.
Le second gros jeu de données extractibles des réseaux sociaux est l'ensemble des « Like » et des « Follow » d'un utilisateur. En filtrant ces données pour ne conserver que les entrées à propos de marques, produits, genres de films, activités sportives, etc., il est possible de constituer un ensemble de mots-clés susceptibles de correspondre à des produits que nous vendons et qui pourront être recommandés à l'utilisateur.
Ce type de recommandations peut s'appuyer sur un autre des projets de la fondation Apache : Lucene, ou sur son « héritier » ElasticSearch, tous deux des moteurs de recherche distribués.
Alors, pourquoi ne pas injecter ces données dans un DataModel Mahout ?
Il semblerait logique par exemple d'attribuer une préférence de 10 à tous les produits électroménagers de cette célèbre marque dont l'utilisateur vient juste de « liker » la page, puis de laisser Mahout faire le difficile travail de clustering et classification. Le problème est que Mahout ne recommande pas les objets directement liés à l'utilisateur, ce qui semble logique sinon on se verrait recommander les produits qu'on vient de visiter. Il faut donc faire ces calculs « manuellement » en trouvant des règles de classification pertinentes (nombre d'occurrences, âge du « Like », etc.).
VII. Conclusion▲
Au cours de cet article, j'ai pu vous présenter rapidement comment s'utilisait Apache Mahout Taste et quelques pistes étudiées pour étendre ses fonctionnalités. L'algorithme en lui-même n'est bien sûr pas réservé qu'aux seules applications e-commerce, la puissance des recommandations personnalisées peut être utilisée pour des choses aussi diverses que les suggestions de comptes Twitter ou de chaînes YouTube. Pourquoi ne pas imaginer l'utiliser pour suggérer des actions ou des activités sur les très lourds logiciels de CRM et gestion d'actifs ?
Les applications sont presque infinies !
VIII. Remerciements▲
Cet article a été publié avec l'aimable autorisation de SQLI qui est le partenaire de référence des entreprises dans la définition, la mise en œuvre et le pilotage de leur transformation digitale.
Nous tenons à remercier Claude Leloup pour la relecture orthographique et milkoseck pour la mise au gabarit.